Xiaojian Xu
Publications
Teaching
CV
Xiaojian Xu (许晓健)
PhD in CS, Washington University in St. Louis
Follow
St. Louis, MO
Email
ResearchGate
Twitter
Facebook
Github
Google Scholar
Publications (selected)
Google Scholar
(* equal contribution)
2023
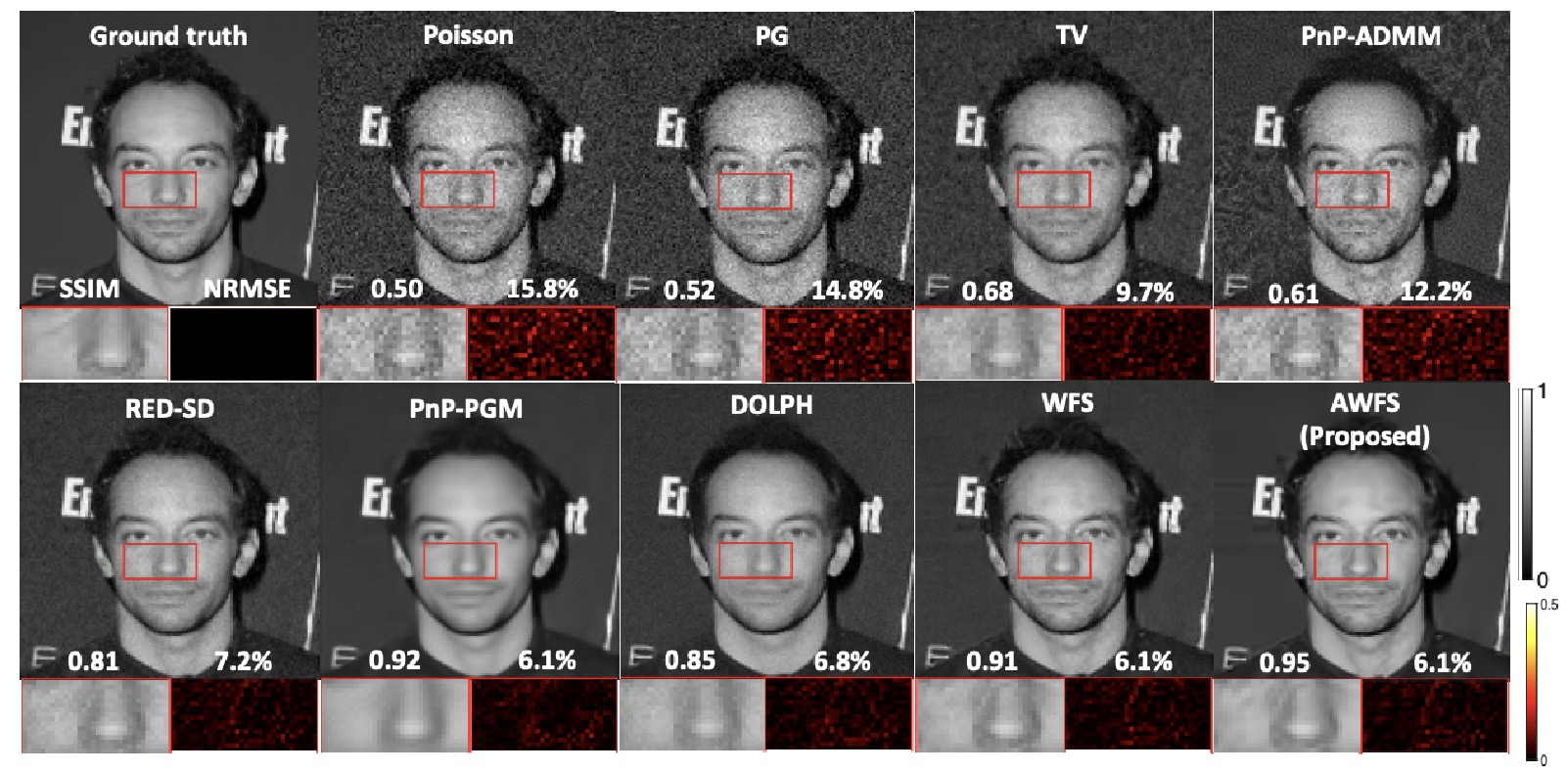
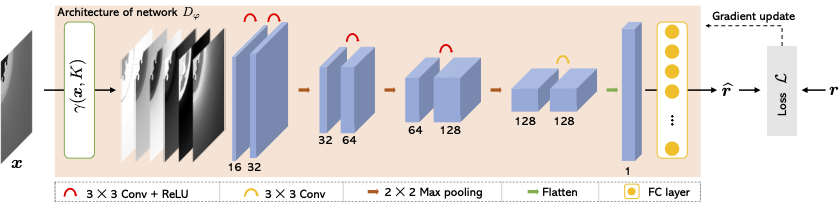
Poisson-Gaussian Holographic Phase Retrieval with Score-based Image Prior
Zongyu Li
,
Jason Hu
,
Xiaojian Xu
,
Liyue Shen
,
Jeffrey Fessler
ArXiv
/
An End-to-End Learning Approach for Subpixel Feature Extraction
Xiaojian Xu
,
Jeffrey Fessler
,
Marc Klasky
,
GS Sidharth
,
Jennifer Schei
Michael McCann
Optica Imaging Congress
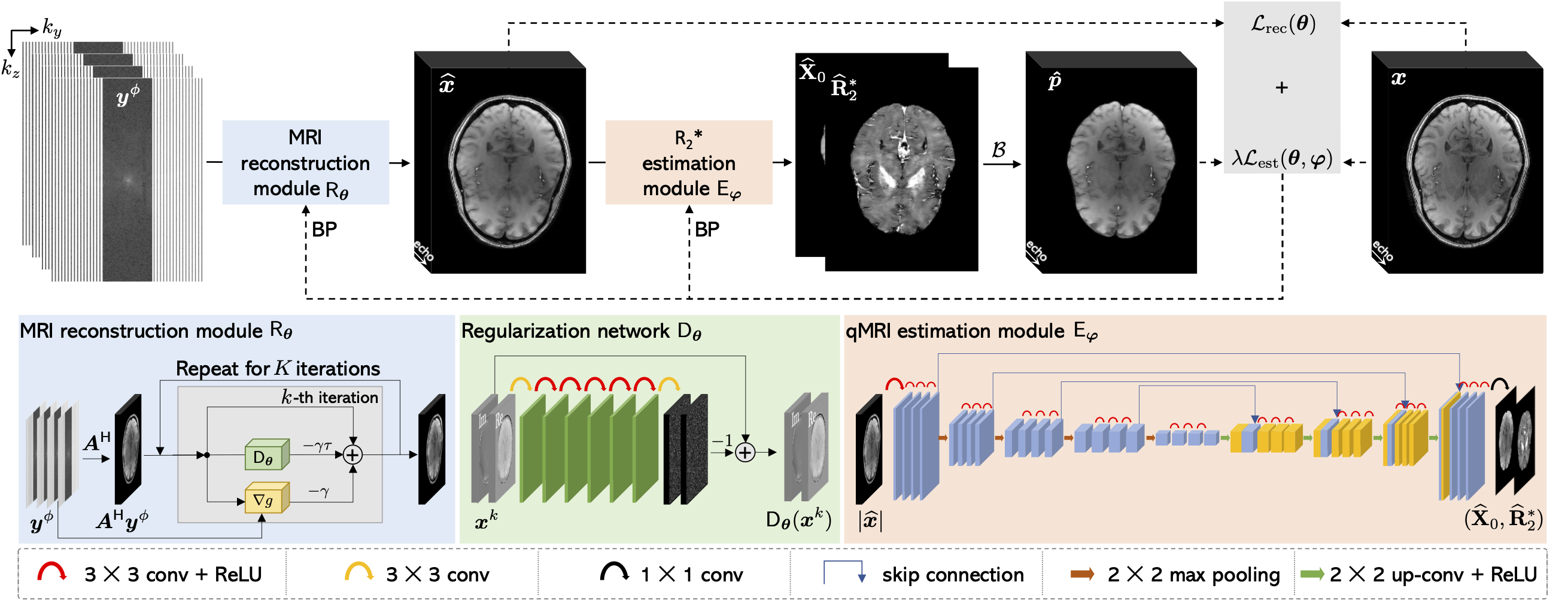
CoRRECT: A Deep Unfolding Framework for Motion-Corrected Quantitative R2* Mapping
Xiaojian Xu*
,
Weijie Gan
,
Satya V.V.N. Kothapalli
,
Dmitriy Yablonskiy
,
Ulugbek Kamilov
ArXiv
2022
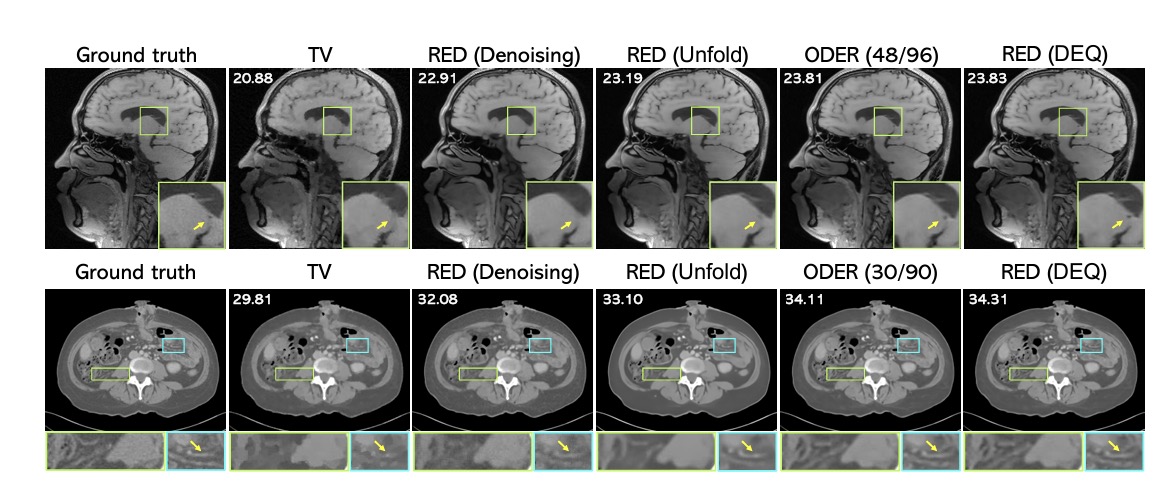
Online Deep Equilibrium Learning for Regularization by Denoising
Xiaojian Xu*
,
Jiaming Liu*
,
Shirin Shoushtari
,
Weijie Gan
,
Ulugbek Kamilov
NeurIPS
Bregman Plug-And-Play Priors
Xiaojian Xu*
,
Abdullah H Al-Shabili*
,
Ivan Selesnick
,
Ulugbek Kamilov
ICIP
2021
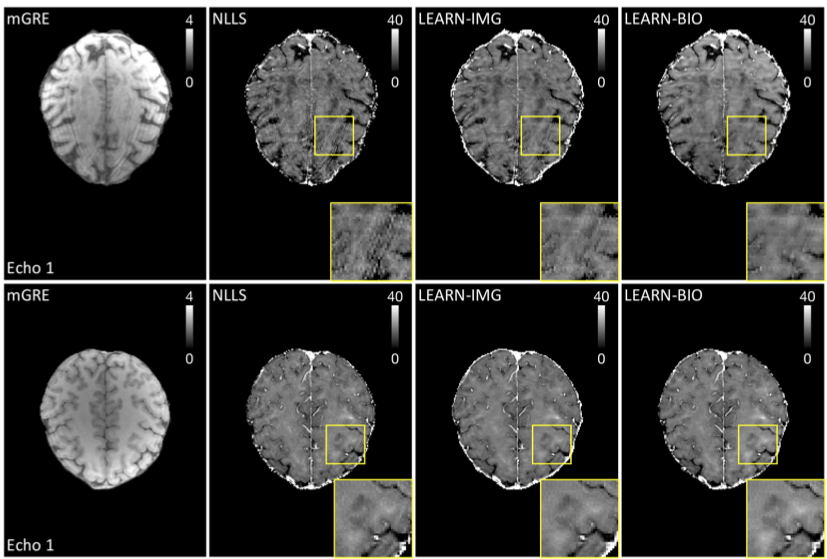
Learning-based Motion Artifact Removal Networks (LEARN) for Quantitative R2* Mapping
Xiaojian Xu
,
Satya V.V.N. Kothapalli
,
Jiaming Liu
,
Sayan Kahali
,
Weijie Gan
,
Dmitriy Yablonskiy
,
Ulugbek Kamilov
MRM
/
Code
/
Poster
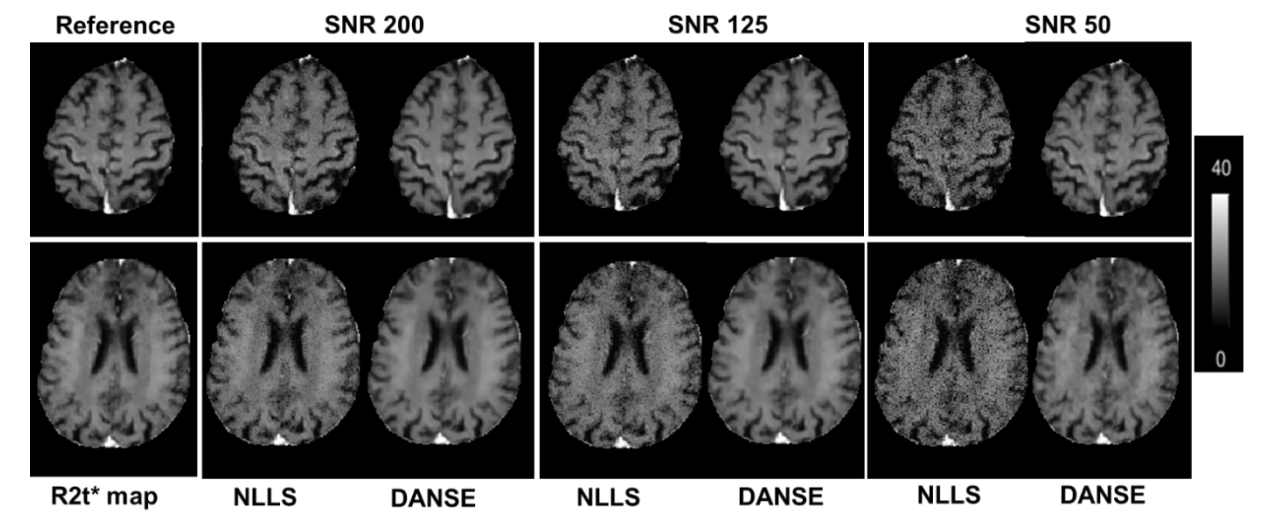
Deep-Learning-Based Accelerated and Noise-Suppressed Estimation (DANSE) of quantitative Gradient Recalled Echo (qGRE) MRI metrics associated with Human Brain Neuronal Structure and Hemodynamic Properties
Sayan Kahali
,
Satya V.V.N. Kothapalli
,
Xiaojian Xu
,
Ulugbek Kamilov
Dmitriy Yablonskiy
NMR Biomed
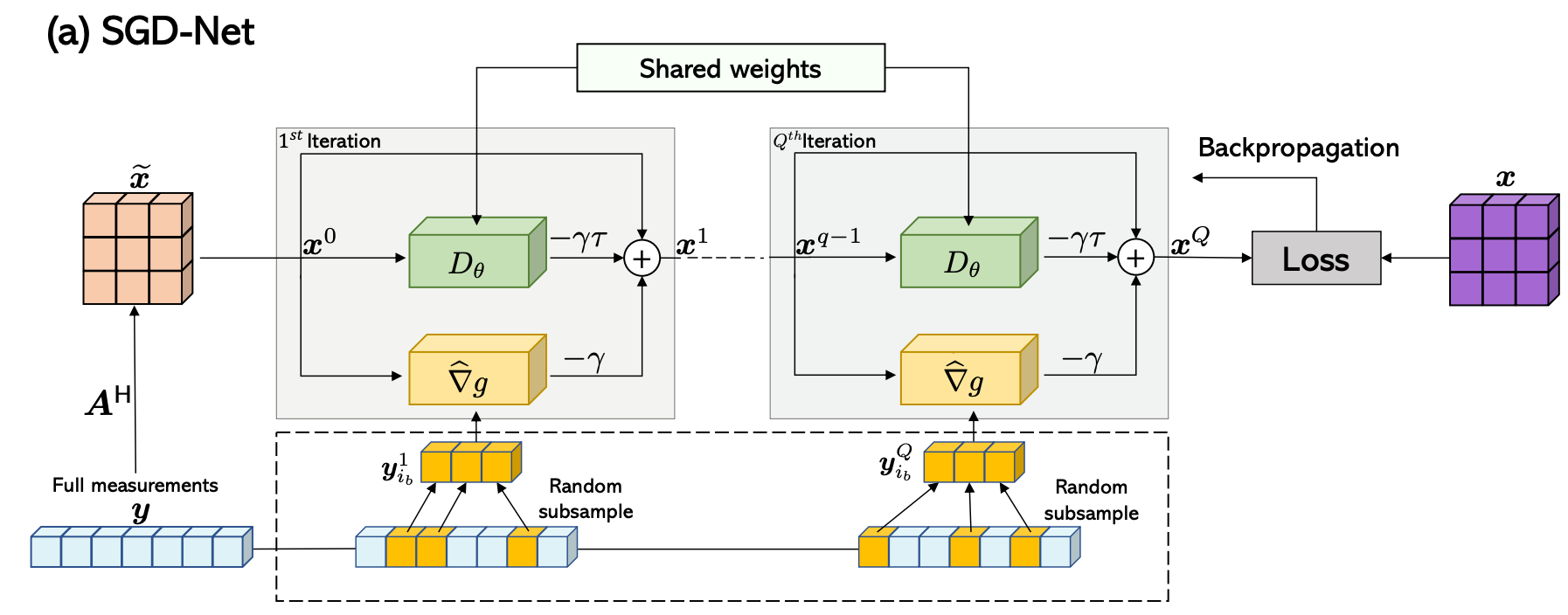
SGD-Net: Efficient Model-Based Deep Learning with Theoretical Guarantees
Jiaming Liu
,
Yu Sun
,
Weijie Gan
,
Xiaojian Xu
,
Brendt Wohlberg
,
Ulugbek Kamilov
IEEE TCI
/
ICASSP
/
arXiv
2020
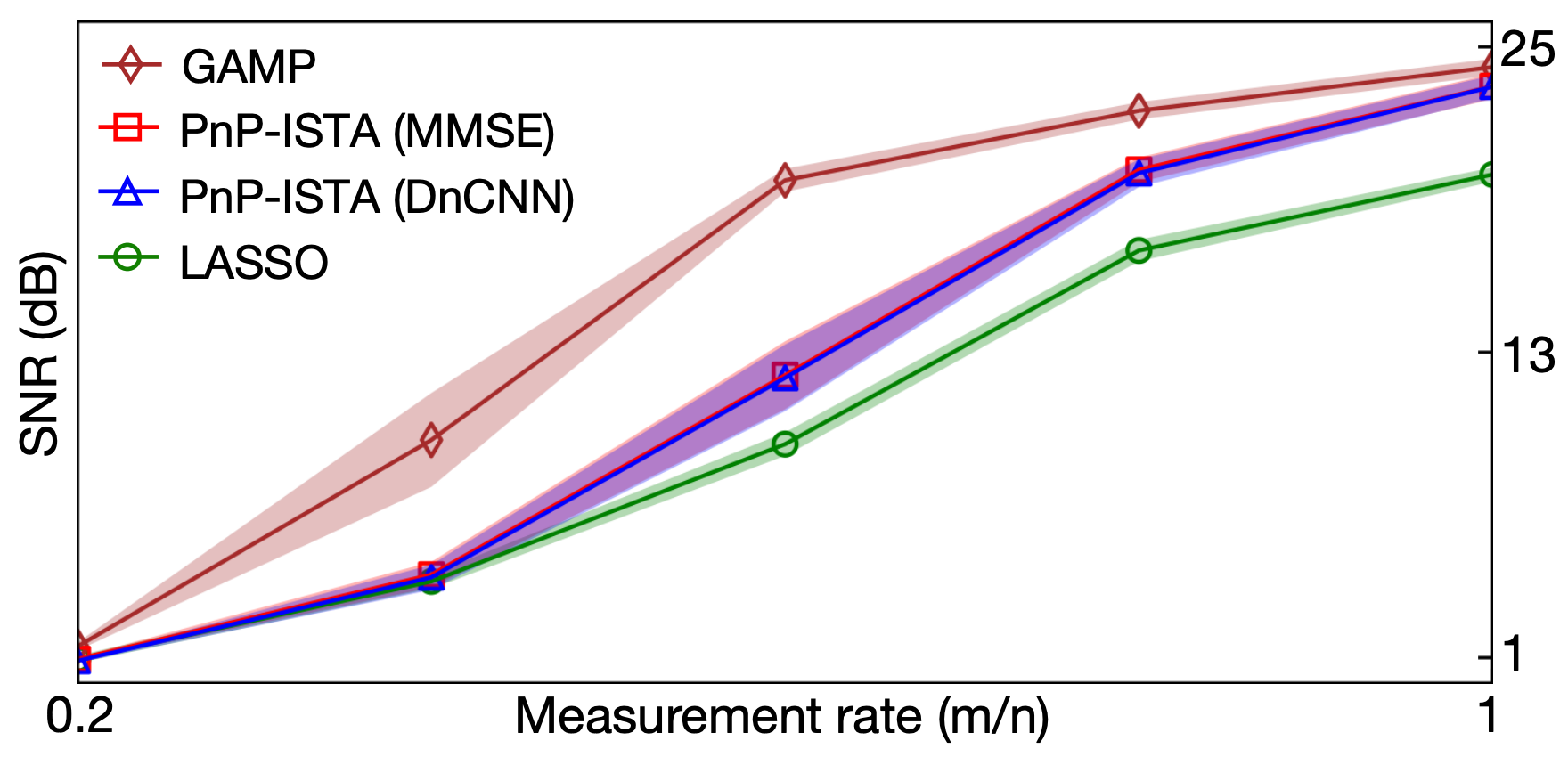
Scalable Plug-and-Play ADMM with Convergence Guarantees
Xiaojian Xu*
,
Yu Sun*
,
Zihui Wu*
,
Brendt Wohlberg
,
Ulugbek Kamilov
IEEE TCI
/
arXiv
Provable Convergence of Plug-and-Play Priors With MMSE Denoisers
Xiaojian Xu
,
Yu Sun
,
Jiaming Liu
,
Brendt Wohlberg
,
Ulugbek Kamilov
IEEE SPL
Boosting the performance of plug-and-play priors via denoiser scaling
Xiaojian Xu
,
Jiaming Liu
,
Yu Sun
,
Brendt Wohlberg
,
Ulugbek Kamilov
Asilomar 2020
/
Slides
Oral presentation
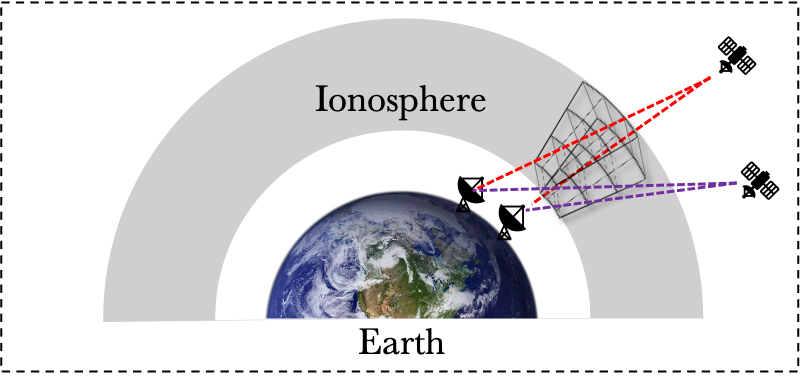
Robust 3D Tomographic Imaging of the Iononspheric Electron Density
Xiaojian Xu
,
Oussama Dhifallah
,
Hassan Mansour
,
Petros Boufounos
,
Philip Orlik
IGARSS
/
Slides
Oral presentation
2019
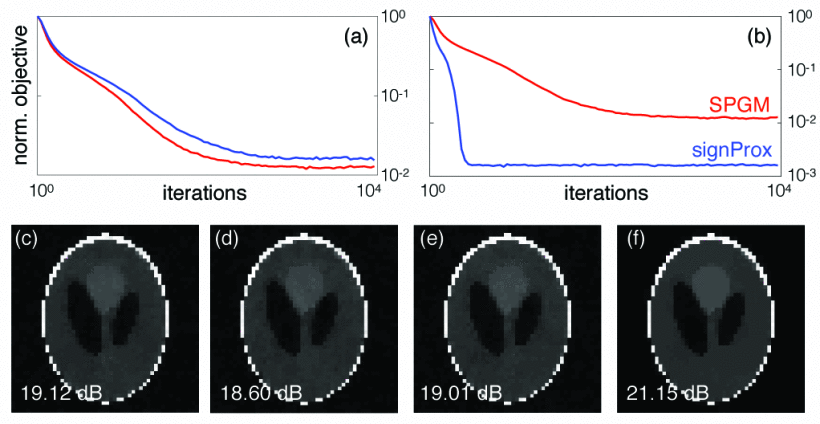
Signprox: One-bit proximal algorithm for nonconvex stochastic optimization
Xiaojian Xu
,
Ulugbek Kamilov
ICASSP 2019
/
Slides
Oral presentation
Image Restoration Using Total Variation Regularized Deep Image Prior
Jiaming Liu
,
Yu Sun
,
Xiaojian Xu
,
Ulugbek Kamilov
ICASSP 2019
/
Poster